event <- replicate(100000, {
die_1 <- sample(x = 1:6, size = 1, replace = TRUE)
die_2 <- sample(x = 1:6, size = 1, replace = TRUE)
(die_1 == 2 * die_2) | (die_2 == 2 * die_1)
})
mean(event)[1] 0.16729When rolling two dice, what is the probability that one die is twice the other?
Besides the classical way of enumerating all events outcomes, we can also tackle this problem in the following way:
let’s consider two dice - one black and one white. The event that one die shows twice what the other die shows can be thought of as the union of two events: either the black die shows twice what the white die shows (Event A), or the white die shows twice what the black die shows (Event B). These two events are mutually exclusive, so the probability of either event happening is the sum of the probabilities of each event happening.
Now, let’s suppose we roll the black die first and then the white die. If the black die shows an odd number, then we know that Event A cannot happen. However, if the black die shows an even number, there is exactly one number on the white die that will result in Event A happening. Since there are n possible numbers on a die (assuming n is even), the probability of Event A happening is \frac{1}{2} \cdot \frac{1}{n}.
By symmetry, the probability of Event B happening is also \frac{1}{2} \cdot \frac{1}{n}. Therefore, the probability of either Event A or Event B happening is P(A \cup B) = 2 \cdot \frac{1}{2} \cdot \frac{1}{n}.
comming back to our particular case, it means:
P(E) = 2 \cdot \frac{1}{2} \cdot \frac{1}{6} = \frac{1}{6}
we can simulate this experiment in R as follow:
event <- replicate(100000, {
die_1 <- sample(x = 1:6, size = 1, replace = TRUE)
die_2 <- sample(x = 1:6, size = 1, replace = TRUE)
(die_1 == 2 * die_2) | (die_2 == 2 * die_1)
})
mean(event)[1] 0.16729Consider an experiment where you roll two dice, and subtract the smaller value from the larger value (getting 0 in case of a tie).
The probability of getting 0 is the probability of getting a tie. This is the probability of getting the same number on both dice.
E = \{(1,1), (2,2), (3,3), (4,4), (5,5), (6,6) \}
and we have 6 \cdot 6 = 36 possible outcomes. So:
P(E) = \frac{6}{36} = \frac{1}{6}
we can simulate this experiment in R as follow:
event <- replicate(100000, {
die_1 <- sample(x = 1:6, size = 1, replace = TRUE)
die_2 <- sample(x = 1:6, size = 1, replace = TRUE)
die_1 == die_2
})
mean(event)[1] 0.16885The probability of getting 4 is the probability of getting a difference of 4.
E = \{(1,5), (5,1), (2,6), (6,2) \}
and we have 6 \cdot 6 = 36 possible outcomes. So:
P(E) = \frac{4}{36} = \frac{1}{9}
we can simulate this experiment in R as follow:
event <- replicate(100000, {
die_1 <- sample(x = 1:6, size = 1, replace = TRUE)
die_2 <- sample(x = 1:6, size = 1, replace = TRUE)
abs(die_1 - die_2) == 4
})
mean(event)[1] 0.11138A hat contains slips of paper numbered 1 through 6. You draw two slips of paper at random from the hat, without replacing the first slip into the hat.
We can write the sample space as:
S = \{(1,2), (1,3), \cdots , (6,5) \}
We can write the event as:
E = \{(1,3), (3,1) \}
We have 6 \cdot 5 = 30 possible outcomes. So:
P(E) = \frac{2}{30} = \frac{1}{15}
we can simulate it in R as follows:
event <- replicate(100000, {
hat <- sample(x = 1:6, size = 2, replace = FALSE)
sum(hat) == 4
})
mean(event)[1] 0.06602Since we cannot draw the same number twice:
F = \emptyset
P(F) = 0
Suppose there are two boxes and each contain slips of papers numbered 1-8. You draw one number at random from each box.
There are 8 \cdot 8 = 64 possible outcomes. The number of outcomes where the sum is 8 is:
E = \{(1,7), (2,6), \cdots, (7,1) \} and the probability is:
P(E) = \frac{7}{64}
We can simulate this experiment in R as follows:
event <- replicate(100000, {
box_1 <- sample(x = 1:8, size = 1, replace = TRUE)
box_2 <- sample(x = 1:8, size = 1, replace = TRUE)
sum(box_1 + box_2) == 8
})
mean(event)[1] 0.10945Similarly, the number of outcomes where at least one of the numbers is 2 is:
E = \{(1,2), (2,1), (2,2), (2,3), \cdots, (8,2) \}
and the probability is:
P(E) = \frac{15}{64}
We can simulate this experiment in R as follows:
event <- replicate(100000, {
box_1 <- sample(x = 1:8, size = 1, replace = TRUE)
box_2 <- sample(x = 1:8, size = 1, replace = TRUE)
box_1 == 2 | box_2 == 2
})
mean(event)[1] 0.23232Suppose the proportion of M&M’s by color is:
| Color | Proportion |
|---|---|
| Yellow | 0.14 |
| Red | 0.13 |
| Orange | 0.20 |
| Brown | 0.12 |
| Green | 0.20 |
| Blue | 0.21 |
Using the law of complement, we have:
P(\neg \text{G}) = 1 - P(\text{G}) = 0.80
We can use the law of addition to find the probability of getting red, orange, or yellow:
P(\text{R} \cup \text{O} \cup \text{Y}) = P(\text{R}) + P(\text{O}) + P(\text{Y})
P(\text{R} \cup \text{O} \cup \text{Y}) = 0.13 + 0.20 + 0.14
P(\text{R} \cup \text{O} \cup \text{Y}) = 0.47
By the law of complement the probability of not getting a blue is 1 - 0.21 = 0.79 and the probability of not getting a blue in four selections is (0.79)^4 = 0.39. Then the probability of getting at least one blue in four selections is:
P(E) = 1 - P(\neg E) = 1 - 0.39 = 0.61
We can simulate this experiment in R as follows:
event <- replicate(100000, {
mms <- sample(x = c("yellow", "red", "orange", "brown", "green", "blue"),
size = 4, p = c(0.14, 0.13, 0.20, 0.12, 0.20, 0.21), replace = TRUE)
"blue" %in% mms
})
mean(event)[1] 0.61046The probability of selecting six M&M’s that contain all six colors is (consdiering ordering):
we need to calculate the total number of ways we can select six M&M’s from a total of 6 colors, with a sample size of 6. That is 6!. Then the probability is:
P(F) = 6! \cdot P(E) = 0.0132
We can simulate this experiment in R as follows:
event <- replicate(100000, {
mms <- sample(x = c("yellow", "red", "orange", "brown", "green", "blue"),
size = 6, p = c(0.14, 0.13, 0.20, 0.12, 0.20, 0.21), replace = TRUE)
length(unique(mms)) == 6
})
mean(event)[1] 0.01337With the distribution from Problem 2.5, suppose you buy a bag of M&M’s with 30 pieces in it. Estimate the probability of obtaining at least 9 Blue M&M’s and at least 6 Orange M&M’s in the bag.
Since I’m not quite sure on how to calculate this without the binomial distribution, lets go directly with the R simulation
event <- replicate(100000, {
mms <- sample(x = c("yellow", "red", "orange", "brown", "green", "blue"),
size = 30, p = c(0.14, 0.13, 0.20, 0.12, 0.20, 0.21), replace = TRUE)
sum(mms == "blue") >= 9 & sum(mms == "orange") >= 6
})
mean(event)[1] 0.06586Blood types O, A, B, and AB have the following distribution in the United States:
| Type | A | AB | B | O |
|---|---|---|---|---|
| Probability | 0.40 | 0.04 | 0.11 | 0.45 |
What is the probability that two randomly selected people have the same blood type?
Since getting the same blood type is an independent event, we can calculate the probability of getting the same blood type by multiplying the probability of getting each blood type. That is:
P(E) = 0.40^2 + \cdots + 0.45^2 = 0.3762
We can simulate this experiment in R as follows:
event <- replicate(100000, {
person_1 <- sample(x = c("A", "AB", "B", "O"),
size = 1, p = c(0.40, 0.04, 0.11, 0.45), replace = TRUE)
person_2 <- sample(x = c("A", "AB", "B", "O"),
size = 1, p = c(0.40, 0.04, 0.11, 0.45), replace = TRUE)
person_1 == person_2
})
mean(event)[1] 0.37671Use simulation to estimate the probability that a 10 is obtained when two dice are rolled.
Besides the simulation, we can also calculate the probability of getting a 10. The event space is: E = \{(6,4), (5,5), (4,6)\}
And the possible outcomes are 6 \cdot 6 = 36. Then the probability of getting a 10 is:
P(\text{10}) = \frac{3}{36} = 0.0833
We can simulate this in R as follow:
event <- replicate(100000, {
dice_1 <- sample(x = 1:6, size = 1, replace = TRUE)
dice_2 <- sample(x = 1:6, size = 1, replace = TRUE)
dice_1 + dice_2 == 10
})
mean(event)[1] 0.08238Estimate the probability that exactly 3 heads are obtained when 7 coins are tossed.
Since it’s a bit long to calculate this one by counting, lets cite and use the definition of the binomial probability
Events where there are only two possible outcomes that we can classify as success or failure, and where the probability of success is known to us as p are called binomial events. When we repeat such events several times, the probability to find r successes in n such repetitions can be calculated by using the expression:
P(r) = \binom{n}{r} p^r (1-p)^{n-r}
where \binom{n}{r} is the binomial coefficient, which is the number of ways of selecting r objects from a set of n objects, where the order of selection does not matter.
Knowing that, we can calculate the probability of getting exactly 3 heads in 7 tosses:
We can simulate this in R as follow:
event <- replicate(100000, {
tosses <- sample(x = c("H", "T"), size = 7, replace = TRUE)
sum(tosses == "H") == 3
})
mean(event)[1] 0.27075We can extend this question by asking what is the probability that at least 3 heads are obtained when 7 coins are tossed. To solve this problem we need to find the probabilities that r could be 3,4,5,6,7 to satisfy the condition “at least”.
P(F) = \sum_{r=3}^{7} \binom{7}{r} (0.5)^r (0.5)^{7-r}
| r | P(F) |
|---|---|
| for r = 3 | \binom{7}{3} (0.5)^3 (0.5)^{4} = 0.2734375 |
| for r = 4 | \binom{7}{4} (0.5)^4 (0.5)^{3} = 0.2734375 |
| for r = 5 | \binom{7}{5} (0.5)^5 (0.5)^{2} = 0.1640625 |
| for r = 6 | \binom{7}{6} (0.5)^6 (0.5)^{1} = 0.0546875 |
| for r = 7 | \binom{7}{7} (0.5)^7 (0.5)^{0} = 0.0078125 |
P(F) = 0.273 + \cdots + 0.007 = 0.773
We could also have calculated this by using the complement of the probability of getting at most 2 heads.
P(F) = 1 - \sum_{r=0}^{2} \binom{7}{r} (0.5)^r (0.5)^{7-r}
| r | P(\text{at most 2 heads}) |
|---|---|
| for r = 0 | \binom{7}{0} (0.5)^0 (0.5)^{7} = 0.0078125 |
| for r = 1 | \binom{7}{1} (0.5)^1 (0.5)^{6} = 0.0546875 |
| for r = 2 | \binom{7}{2} (0.5)^2 (0.5)^{5} = 0.1640625 |
P(F) = 1 - 0.225 = 0.773
We can simulate this in R as follow:
event <- replicate(100000, {
tosses <- sample(x = c("H", "T"), size = 7, replace = TRUE)
sum(tosses == "H") >= 3
})
mean(event)[1] 0.77311Estimate the probability that the sum of five dice is between 15 and 20, inclusive.
We need to count the number of ways that we can roll five dice and get a sum between 15 and 20, and divide that by the total number of possible outcomes when rolling five dice. Since it is a bit long to count all possible combinations of (a,b,c,d,e) where a+b+c+d+e \in [15,20] We are going directly with the simulation.
event <- replicate(100000, {
dice <- sample(x = 1:6, size = 5, replace = TRUE)
sum(dice) >= 15 & sum(dice) <= 20
})
mean(event)[1] 0.55585Suppose a die is tossed repeatedly, and the cumulative sum of all tosses seen is maintained. Estimate the probability that the cumulative sum ever is exactly 20. (Hint: the function cumsum computes the cumulative sums of a vector.)
Again, we are going directly wit the simulation due the overwhelming amount of combinations. We know that 20 is the maximum number of tosses that could have a cumulative sum of 20. So doing a sample of 20 rolls will be enough to get a good estimate.
event <- replicate(100000, {
tosses <- sample(x = 1:6, size = 20, replace = TRUE)
cumulative_sum <- cumsum(tosses)
any(cumulative_sum == 20)
})
mean(event)[1] 0.28733(Rolling two dice)
Simulate rolling two dice and adding their values. Perform 10,000 simulations and make a bar chart showing how many of each outcome occurred.
You can buy trick dice, which look (sort of) like normal dice. One die has numbers 5, 5, 5, 5, 5, 5. The other has numbers 2, 2, 2, 6, 6, 6. Simulate rolling the two trick dice and adding their values. Perform 10,000 simulations and make a bar chart showing how many of each outcome occurred.
Sicherman dice also look like normal dice, but have unusual numbers. One die has numbers 1, 2, 2, 3, 3, 4. The other has numbers 1, 3, 4, 5, 6, 8. Simulate rolling the two Sicherman dice and adding their values. Perform 10,000 simulations and make a bar chart showing how many of each outcome occurred. How does your answer compare to part (a)?
library(ggplot2)
outcomes <- replicate(10000, {
dice_1 <- sample(x = 1:6, size = 1, replace = TRUE)
dice_2 <- sample(x = 1:6, size = 1, replace = TRUE)
dice_1 + dice_2
})
df <- data.frame(outcomes)
ggplot(data = df, mapping = aes(outcomes), fill = "transparent") +
geom_histogram(bins = 11, fill = "transparent", color = "black")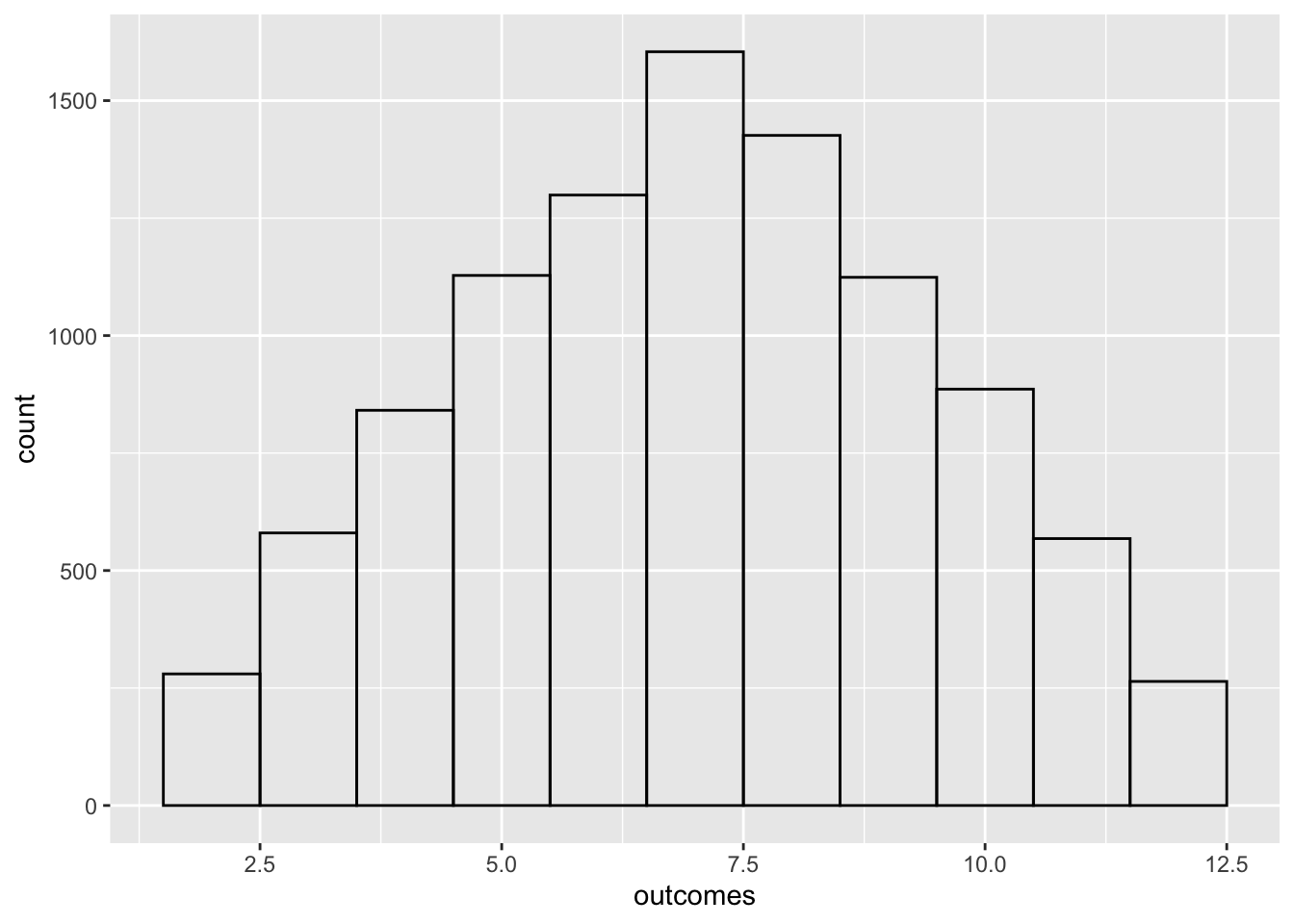
library(ggplot2)
outcomes <- replicate(10000, {
dice_1 <- sample(x = c(5, 5, 5, 5, 5, 5), size = 1, replace = TRUE)
dice_2 <- sample(x = c(2, 2, 2, 6, 6, 6), size = 1, replace = TRUE)
dice_1 + dice_2
})
df <- data.frame(outcomes)
ggplot(data = df, mapping = aes(outcomes), fill = "transparent") +
geom_histogram(bins = 11, fill = "transparent", color = "black")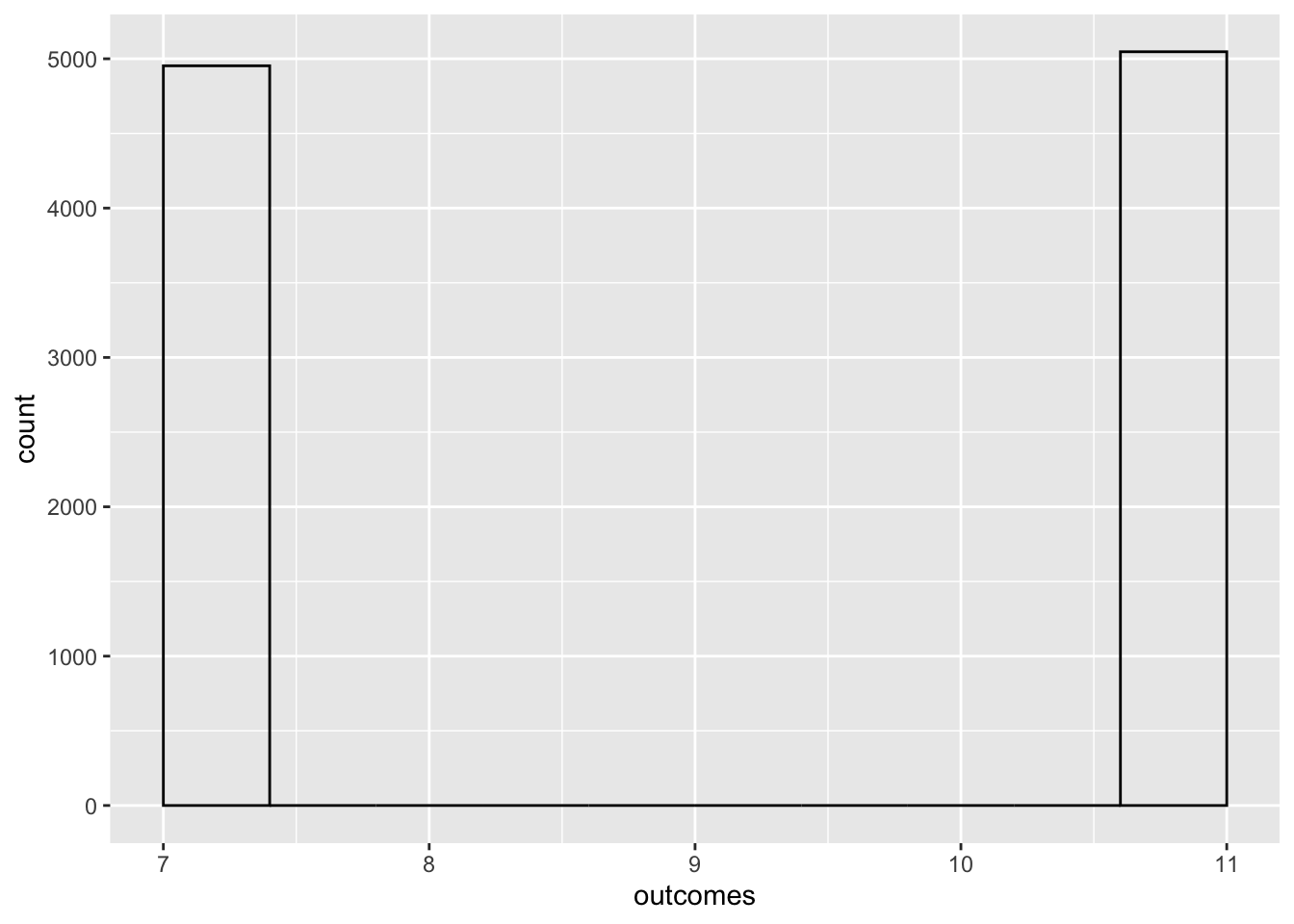
library(ggplot2)
outcomes <- replicate(10000, {
dice_1 <- sample(x = c(1, 2, 2, 3, 3, 4), size = 1, replace = TRUE)
dice_2 <- sample(x = c(1, 3, 4, 5, 6, 8), size = 1, replace = TRUE)
dice_1 + dice_2
})
df <- data.frame(outcomes)
ggplot(data = df, mapping = aes(outcomes), fill = "transparent") +
geom_histogram(bins = 11, fill = "transparent", color = "black")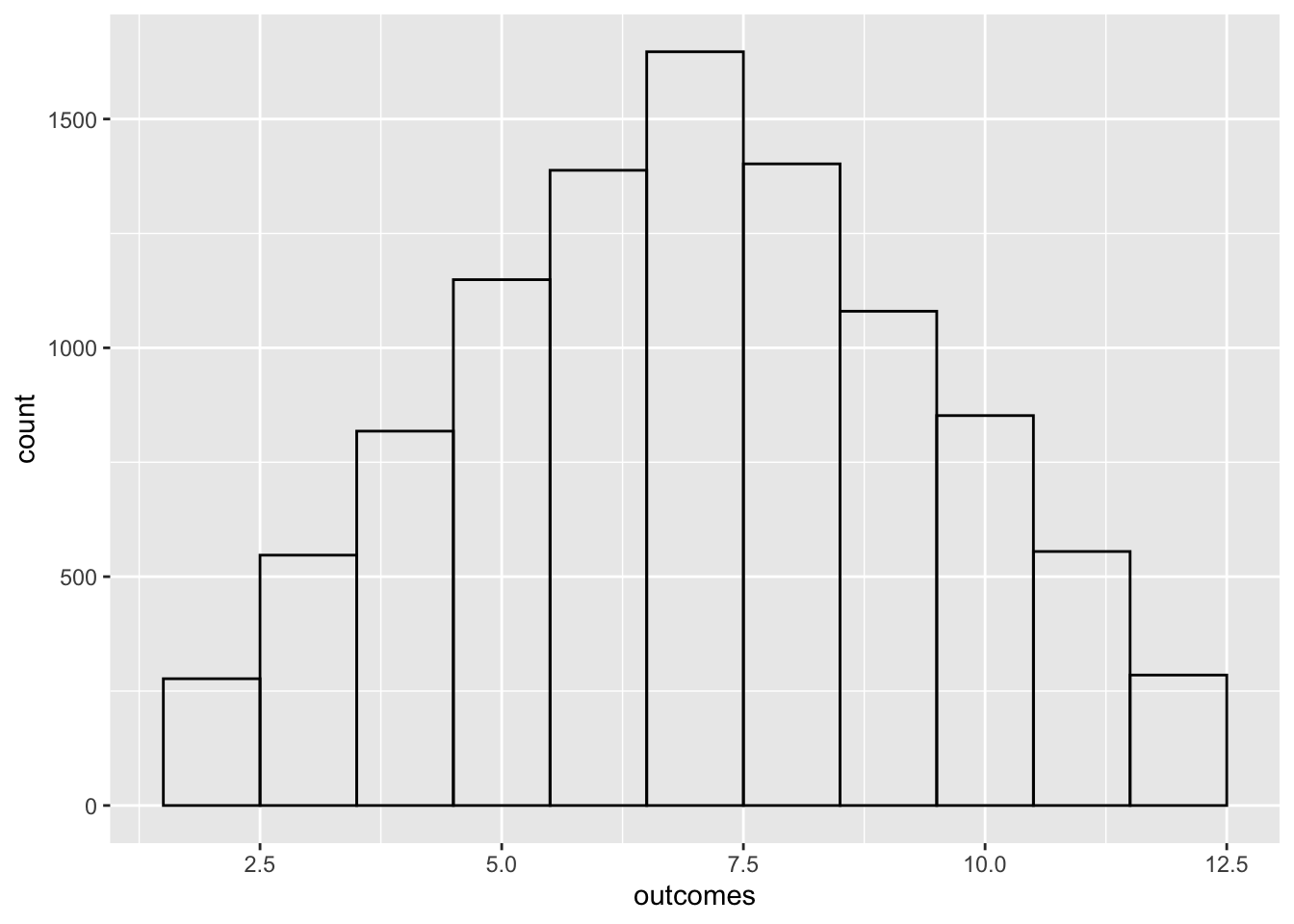
They have the same distribution.
In a room of 200 people (including you), estimate the probability that at least one other person will be born on the same day as you.
we can use the complement rule and calculate the probability that none of the other 199 people share the same birthday as me. Assuming that birthdays are uniformly distributed across all 365 days of the year (ignoring leap years), the probability that any given person in the room was not born on the same day as me is:
P(E) = \left(\frac{1}{365}\right)^{199} = 0.58
And the probability that at least one other person has the same birthday as you is:
P(F) = 1 - P(E) = 0.42
we can simulate this in R as follow:
event <- replicate(100000, {
my_birthday <- sample(x = 1:365, size = 1, replace = TRUE)
other_people_birthdays <- sample(x = 1:365, size = 199, replace = TRUE)
any(other_people_birthdays == my_birthday)
})
mean(event)[1] 0.42299In a room of 100 people, estimate the probability that at least two people were not only born on the same day, but also during the same hour of the same day. (For example, both were born between 2 and 3.)
Assuming each person birth is uniformly distributed across all 24 hours of the day, and all 365 days of the year (ignoring leap years). The probability that any two people were born during the same hour of the same day is:
P(E) = \frac{1}{24} \cdot \frac{1}{365} = 0.0001
Then the probability that none of the 100 people were born on the same day and during the same hour can be expressed as:
F: None of the 100 people were born on the same day and during the same hour
P(F) = \left(1 - P(E)\right)^{\binom{100}{2}} = 0.5683
finally the probability that at least two people were born during the same hour of the same day is:
P(G) = 1 - P(F) = 0.4316
We can simulate this in R as follow:
event <- replicate(100000, {
birthdays <- sample(x = 1:(365 * 24), size = 100, replace = TRUE)
sum(duplicated(birthdays)) >= 1
})
mean(event)[1] 0.42947Assuming that there are no leap-day babies and that all birthdays are equally likely, estimate the probability that at least three people have the same birthday in a group of 50 people. (Hint: try using table.)
The probability of the birthday problem becomes increasingly complicated with more people, as the complementary event includes a larger number of possibilities that need to be accounted for. For example, for three people, the complementary event not only includes the possibility that all three birthdays are distinct, but also the possibilities of having one pair with the rest distinct, two pairs with the rest distinct, and so on. Calculating the exact value can be quite complicated.
I’m going to use the Poisson approximation to calculate the probability of the birthday problem. The Poisson approximation is a good approximation for large values of n and small values of p. In this case, n = 50 and p = \frac{1}{365}. However, the autor maybe want us to only simulate the problem, because at this chapter we are not supposed to know the Poisson approximation.
One way to approach this is by considering every group of three people and calling it a “success” if they all share the same birthday. This can be modeled as a Poisson distribution, where the expected number of “successes” is the number of groups of three people times the probability that three people share the same birthday.
The total number of successes is approximately Poisson with mean value \frac{\binom{50}{3}}{365^{2}}. Here \binom{50}{3} is the number of triples, and \frac{1}{365^{2}} is the chance that any particular triple is a success. The probability of getting at least one success is obtained from the Poisson distribution:
We can simulate this in R as follow:
event <- replicate(100000, {
birthdays <- sample(x = 1:365, size = 50, replace = TRUE)
birthday_table <- table(birthdays)
length(birthday_table[birthday_table >= 3])
})
mean(event)[1] 0.1339If 100 balls are randomly placed into 20 urns, estimate the probability that at least one of the urns is empty.
The probability of choose an specific urn is \frac{1}{20} then the probability of not choose an specific urn is \frac{19}{20} and the probability of not choose an specific urn 100 times is \left(\frac{19}{20}\right)^{100}. To get the probability of at least one urn is empty we need to multiply this by the number of urns:
P(E) = \left(\frac{19}{20}\right)^{100} \cdot 20 = 0.1184
We can simulate this in R as follow:
event <- replicate(100000, {
selected_urns <- sample(x = 1:20, size = 100, replace = TRUE)
length(unique(selected_urns)) < 20
})
mean(event)[1] 0.11309A standard deck of cards has 52 cards, four each of 2,3,4,5,6,7,8,9,10,J,Q,K,A. In blackjack, a player gets two cards and adds their values. Cards count as their usual numbers, except Aces are 11 (or 1), while K, Q, J are all 10.
We can see it as follow:
First event (getting an 11 card): There are 4 aces in a pack, and we’ve got a full pack (52 cards), so the probability of getting one of the aces first is 4 out of 52 \frac{4}{52}. Second event (getting a 10 card): There are 16 cards worth 10 in a pack (4 of each of 10, J, Q, K), but we’ve already got one of the cards from the back, so the probability of getting a 10 now is 16 out of 51 \frac{16}{51}. We want event 1 AND event 2 to happen, so we have to multiply the probabilities: \frac{4}{52} \cdot \frac{16}{51} = \frac{64}{2652}
First event (getting a 10 card): There are 16 cards worth 10, as before, but this time we’ve got a full pack, so the probability is \frac{16}{52}. Second event (getting an 11 card): There are 4 aces, as before, but this time we’ve got rid of one card, so the probability is \frac{4}{51}. Again, we want event 1 AND event 2 to happen: \frac{4}{51} \cdot \frac{16}{52} = \frac{64}{2652}
Now, we want either option 1 OR option 2to happen (because either way will give us a blackjack). There’s an OR there, so we’ve got to add the two probabilities together:
P(E) = 0.048
We can simulate this in R as follow:
deck <- c("2", "3", "4", "5", "6", "7", "8", "9", "10", "10", "10", "10", "A")
event <- replicate(100000, {
cards <- sample(x = deck, size = 2, replace = TRUE)
(cards[1] == "A" && cards[2] == "10") ||
(cards[1] == "10" && cards[2] == "A")
})
mean(event)[1] 0.04763We can see it as follow:
So we can calculate the probability similarly as the previous problem:
P(E) = 0.060
We can simulate this in R as follow:
deck <- c("2", "3", "4", "5", "6", "7", "8", "9", "10", "10", "10", "10", "A")
event <- replicate(100000, {
cards <- sample(x = deck, size = 2, replace = TRUE)
(cards[1] == "9" && cards[2] == "10") ||
(cards[1] == "10" && cards[2] == "9") ||
(cards[1] == "A" && cards[2] == "8") ||
(cards[1] == "8" && cards[2] == "A")
})
mean(event)[1] 0.05815Deathrolling in World of Warcraft works as follows. Player 1 tosses a 1000-sided die. Say they get x_{1}. Then player 2 tosses a die with x_{1} sides on it. Say they get x_{2}. Player 1 tosses a die with x_{2} sides on it. This pattern continues until a player rolls a 1. The player who loses is the player who rolls a 1. Estimate via simulation the probability that a 1 will be rolled on the 4th roll in deathroll.
event <- replicate (100000, {
x1 <- sample(x = 1:1000, size = 1, replace = TRUE)
x2 <- sample(x = 1:x1, size = 1, replace = TRUE)
x3 <- sample(x = 1:x2, size = 1, replace = TRUE)
x4 <- sample(x = 1:x3, size = 1, replace = TRUE)
x4 == 1
})
mean(event)[1] 0.07554In the game of Scrabble, players make words using letter tiles. The data set fosdata::scrabble contains all 100 tiles. Estimate the probability that a player’s first seven tiles contain no vowels. (Vowels are A, E, I, O, and U.)
Letter tiles in Scrabble are distributed as follow:
| Frequency | Letters |
|---|---|
| 1 | Q, Z, J, X, K |
| 2 | B, C, F, H, M, P, V, W, Y, (black tile) |
| 3 | G |
| 4 | D, L, S, U |
| 6 | N, R, T |
| 8 | O |
| 9 | A, I |
| 12 | E |
The total number of vowels is:
N_{\text{vowels}} = 9 + 12 + 9 + 8 + 4 = 42
That means there is a total of 58 non vowels in the scrabble set, so the probability of getting no vowels is:
P(E) = \frac{58\cdot 57 \cdots 52}{100 \cdot 99 \cdots 94}
P(E) = 0.019
We can simulate this in R as follow:
library(fosdata)
event <- replicate(100000, {
tiles <- sample(x = fosdata::scrabble$piece, size = 7, replace = FALSE)
!any(tiles %in% c("A", "E", "I", "O", "U"))
})
mean(event)[1] 0.0195Two dice are rolled.
The probability of getting a 10 is:
E = \{ (6,4), (4,6), (5,5) \}
P(E) = \frac{3}{36} = 0.083
We can simulate this in R as follow:
event <- replicate(100000, {
dice1 <- sample(x = 1:6, size = 1, replace = TRUE)
dice2 <- sample(x = 1:6, size = 1, replace = TRUE)
dice1 + dice2 == 10
})
mean(event)[1] 0.08453The probability of getting a 10 or more is:
E = \{ (6,6), (6,5), \cdots, (5,5) (4,6)\}
P(E) = \frac{6}{36} = 0.167
We can simulate this in R as follow:
event <- replicate(100000, {
dice1 <- sample(x = 1:6, size = 1, replace = TRUE)
dice2 <- sample(x = 1:6, size = 1, replace = TRUE)
dice1 + dice2 >= 10
})
mean(event)[1] 0.16767P(A|B) = \frac{P(A \cap B)}{P(B)}
P(A|B) = \frac{\frac{3}{36}}{\frac{6}{36}} = \frac{1}{2}
A hat contains six slips of paper with the numbers 1 through 6 written on them. Two slips of paper are drawn from the hat (without replacing), and the sum of the numbers is computed.
The probability of getting a 10 is:
E = \{ (6,4), (4,6) \}
And we have 6 (first draw) times 5 (second draw) = 30 ways to draw two slips of paper.
P(E) = \frac{2}{30} = 0.067
We can simulate this in R as follow:
event <- replicate(100000, {
slips <- sample(x = 1:6, size = 2, replace = FALSE)
sum(slips) == 10
})
mean(event)[1] 0.06729The probability of getting a 10 or more is:
E = \{ (4,6), (5,6), (6, 4), (6,5)\}
As like before,
P(E) = \frac{4}{30} = 0.133
We can simulate this in R as follow:
event <- replicate(100000, {
slips <- sample(x = 1:6, size = 2, replace = FALSE)
sum(slips) >= 10
})
mean(event)[1] 0.13328P(A|B) = \frac{\frac{2}{30}}{\frac{4}{30}} = \frac{1}{2}
Note that P(A \cap B) = P(A) in this and the previous case beacuse “exactly 10” is a subset of “at least 10”. It is not the general case.
Roll two dice, one white and one red. Consider these events:
The following pairs are disjoint:
The following pairs are independent:
The following pairs are neither disjoint nor independent:
Suppose you do an experiment where you select ten people at random and ask their birthdays.
Here are three events:
The following pairs are disjoint:
The following pairs are independent:
It means the probability of all ten people being born in February given that the first person was born in February. Given that A \subset B we can express it as: P(A|B) = \frac{P(A \cap B)}{P(B)} = \frac{P(A)}{P(B)}
P(A|B) = \frac{\left(\frac{1}{12}\right)^{10}}{\frac{1}{12}} = 1.93e-10
Let A and B be events. Show that P(A \cup B | B) = 1 .
P(A \cup B | B) = \frac{P((A \cup B) \cap B)}{P(B)} = \frac{P(B)}{P(B)} = 1
In an experiment where you toss a fair coin twice, define events:
Show that A and B are independent. Show that A and C are independent. Show that B and C are independent. Show that A, B, and C are not mutually independent.
To show that A and B are independent, we need to show that P(A \cap B) = P(A) \cdot P(B).
We can define the sample space as: S = \{(H,H), (H, T), (T, H), (T,T) \}
And the events as:
A = \{(H,H), (H, T)\}
B = \{(H,H), (T, H)\}
C = \{(H,H), (T, T)\}
And the intersections as:
A \cap B = A \cap C = B \cap C = \{(H,H)\}
And the probabilities could be calculated as:
P(A \cap B) = P(A \cap C) = P(B \cap C) = \frac{1}{4}
P(A) = P(B) = P(C) = \frac{2}{4} = \frac{1}{2}
P(A \cap B) = P(A) \cdot P(B)
\frac{1}{4} = \frac{1}{2} \cdot \frac{1}{2}
P(A \cap C) = P(A) \cdot P(C)
\frac{1}{4} = \frac{1}{2} \cdot \frac{1}{2}
P(B \cap C) = P(B) \cdot P(C)
\frac{1}{4} = \frac{1}{2} \cdot \frac{1}{2}
P(A \cap B \cap C) = P(A) \cdot P(B) \cdot P(C)
\frac{1}{4} \neq \frac{1}{2} \cdot \frac{1}{2} \cdot \frac{1}{2}
Suppose a die is tossed three times. Let A be the event “the first toss is a 5”, let B be the event “the first toss is the largest number rolled” (the “largest” can be a tie). Determine, via simulation or otherwise, whether A and B are independent.
event_a_b <- replicate(100000, {
rolls <- sample(x = 1:6, size = 3, replace = TRUE)
a <- rolls[1] == 5
b <- rolls[1] == max(rolls)
a && b
})
a_b <- mean(event_a_b)
event_a <- replicate(100000, {
rolls <- sample(x = 1:6, size = 3, replace = TRUE)
rolls[1] == 5
})
a <- mean(event_a)
event_b <- replicate(100000, {
rolls <- sample(x = 1:6, size = 3, replace = TRUE)
rolls[1] == max(rolls)
})
b <- mean(event_b)
print(paste("P(A and B):", a_b))[1] "P(A and B): 0.1161"print(paste("P(A) * P(B):", a * b))[1] "P(A) * P(B): 0.070339434"As we can see, the probability of A \cap B is not equal to the probability of A times the probability of B. Therefore, they are not independent.
Suppose you have two coins that land with heads facing up with common probability p where 0 < p < 1. One coin is red and the other is white. You toss both coins. Find the probability that the red coin is heads, given that the red coin and the white coin are different. Your answer will be in terms of p
We want to find P(A|C). We can express this probability in terms of conditional probabilities:
P(A|C) = \frac{P(A \cap C)}{P(C)}
We know that P(A) = P(B) = p and P(C) = 2p(1-p), since there are two ways in which the coins can be different (red heads, white tails and red tails, white heads), and each of these ways has probability p(1-p). For P(A \cap C) we can use the fact that A \cap C means the red coin is heads and the white coin is tails, and there is only one way in which this can happen, so P(A \cap C) = p(1-p).
P(A|C) = \frac{p(1-p)}{2p(1-p)} = \frac{1}{2}
we can simulate this experiment to verify our result:
p <- runif(n = 1, min = 0, max = 1)
event_a_and_c <- replicate(100000, {
red <- sample(x = c("H", "T"), size = 1, replace = TRUE, prob = c(p, 1-p))
white <- sample(x = c("H", "T"), size = 1, replace = TRUE, prob = c(p, 1-p))
red == "H" && white != red
})
event_c <- replicate(100000, {
red <- sample(x = c("H", "T"), size = 1, replace = TRUE, prob = c(p, 1-p))
white <- sample(x = c("H", "T"), size = 1, replace = TRUE, prob = c(p, 1-p))
white != red
})
prob_a_and_c <- mean(event_a_and_c)
prob_c <- mean(event_c)
prob_a_and_c / prob_c[1] 0.5046218Bob Ross was a painter with a PBS television show, “The Joy of Painting,” that ran for 11 years.
91% of Bob’s paintings contain a tree and 85% contain two or more trees. What is the probability that he painted a second tree, given that he painted a tree?
18% of Bob’s paintings contain a cabin. Given that he painted a cabin, there is a 35% chance the cabin is on a lake. What is the probability that a Bob Ross painting contains both a cabin and a lake?
We want to find P(B|A), where A is the event “Bob painted a tree” and B is the event “Bob painted a second tree”. We can express this probability in terms of conditional probabilities:
P(B|A) = \frac{P(B \cap A)}{P(A)}
We know that P(A) = 0.91 and P(B) = 0.85. For P(B \cap A) we can use the fact that B \cap A means Bob painted a tree and a second tree, and there is only one way in which this can happen, so P(B \cap A) = 0.85.
P(B|A) = \frac{0.85}{0.91} = 0.93
We want to find P(A \cap B), where A is the event “Bob painted a cabin”, B is the event “The cabin is on a lake”. We can express this probability in terms of conditional probabilities:
P(A \cap B) = P(A)P(B|A)
We know that P(A) = 0.18 and P(B|A) = 0.35, so we can calculate P(A \cap B) as follows:
P(A \cap B) = 0.18 \cdot 0.35 = 0.063
Ultimate frisbee players are so poor they don’t own coins. So, team captains decide which team will play offense first by flipping frisbees before the start of the game. Rather than flip one frisbee and call a side, each team captain flips a frisbee and one captain calls whether the two frisbees will land on the same side, or on different sides. Presumably, they do this instead of just flipping one frisbee because a frisbee is not obviously a fair coin - the probability of one side seems likely to be different from the probability of the other side.
The space of outcomes for flipping two fair coins is: S = \{HH, HT, TH, TT\} .
The event “the two coins show different sides” is:
E = \{HT, TH\}
so the probability of this event is:
P(E) = \frac{2}{4} = \frac{1}{2}
The probability that a frisbee lands convex side up is p and the probability that it lands concave side up is 1-p. So the probability of the both frisbee match is:
P(E) = p^2 + (1-p)^2
p <- seq(0, 1, length.out = 100)
prob <- p^2 + (1-p)^2
plot(p, prob, type = "l", xlab = "p", ylab = "probability of match")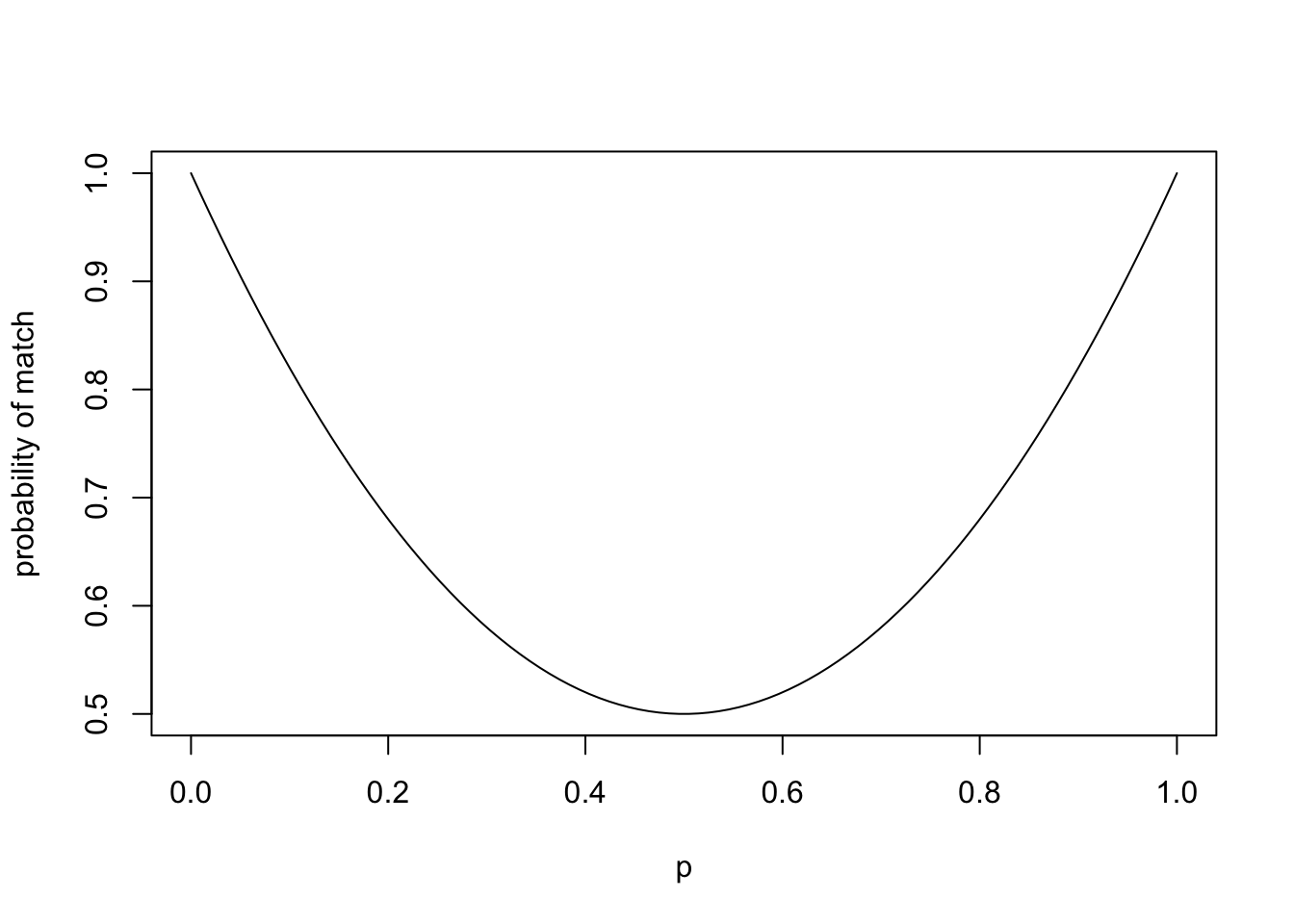
The probability of a match is p^2 + (1-p)^2, so the probability of a non-match is 1 - p^2 - (1-p)^2. If the probability of a convex side up is 0.45, then the probability of a match is:
P(\text{match}) = 0.45^2 + (1-0.45)^2 = 0.505
and the probability of a non-match is:
P(\text{non-match}) = 1 - 0.505 = 0.495
Since the probability of match is slightly higher than the probability of non-match, the captains should call “same” (assuming that they want to play offence first) but the difference is small enough that it doesn’t really matter.
The two-frisbee flip is better than a single-frisbee flip for deciding the offense because the probability of match or non-match is almost a fair coin flip, whereas the probability of a single frisbee is more bias towards the concav side.
Suppose there is a new test that detects whether people have a disease. If a person has the disease, then the test correctly identifies that person as being sick 99.9% of the time (sensitivity of the test). If a person does not have the disease, then the test correctly identifies the person as being well 97% of the time (specificity of the test). Suppose that 2% of the population has the disease. Find the probability that a randomly selected person has the disease given that they test positive for the disease.
We can use Bayes’ theorem to solve this problem:
P(H|E) = \frac{P(E|H)P(H)}{P(E)}
P(E) is more conveniently expressed as:
P(E) = P(E|H)P(H) + P(E|\neg H)P(\neg H)
We know that P(H) = 0.02, P(\neg H) = 0.98, P(E|H) = 0.999 and P(E|\neg H) = 0.03 (false positives). Then We can calculate P(H|E) as follows:
P(H|E) = \frac{0.999 \cdot 0.02}{0.999 \cdot 0.02 + 0.03 \cdot 0.98} = 0.40
Suppose that there are two boxes containing marbles. Box 1 contains 3 red and 4 blue marbles. Box 2 contains 2 red and 5 blue marbles. A single die is tossed, and if the result is 1 or 2, then a marble is drawn from box 1. Otherwise, a marble is drawn from box 2.
We can define the following events:
We can calculate the probability of the marble using the law of total being red as follows:
P(C) = P(C|A)P(A) + P(C|B)P(B)
We know that P(A)=\frac{2}{6}, P(B)=\frac{4}{6}, P(C|A)=\frac{3}{7} and P(C|B)=\frac{2}{7}. So we can calculate P(C) as follows:
P(C) = \frac{3}{7} \cdot \frac{2}{6} + \frac{2}{7} \cdot \frac{4}{6} = \frac{11}{42} = 0.26
We can use Bayes’ theorem to calculate the probability that the marble came from box 1 given that the marble is red:
P(A|C) = \frac{P(C|A)P(A)}{P(C)}
Using the values from part (a), we can calculate P(A|C) as follows:
P(A|C) = \frac{\frac{3}{7} \cdot \frac{2}{6}}{\frac{11}{42}} = \frac{6}{11} = 0.54
Suppose that you have 10 boxes, numbered 0-9. Box i contains i marbles, and 9-i blue marbles.

You perform the following experiment. Pick a box at random, draw a marble and record its color. Replace the marble back in the box, and draw another marble from the same box and record its color. Replace the marble back in the box, and draw another marble from the same box and record its color. So, all three marbles are drawn from the same box.
Let’s first calculate the probability of drawing three consecutive red marbles from a box. We will use conditional probability to solve this problem. Let’s denote the event of drawing three consecutive red marbles as R_{3}, and the event of choosing a box i as B_{i}.
The probability of drawing three consecutive red marbles can be expressed as follows:
P(R_{3}) = \sum_{i=0}^{9} P(R_{3}|B_{i})P(B_{i})
Since we have 10 boxes (numbered 0-9) and we select a box at random, the probability of choosing any box i is:
P(B_{i}) = \frac{1}{10}
Now, let’s calculate the probability of drawing three consecutive red marbles given that we have chosen box i represented by P(R_{3} | B_{i}). The probability of drawing a red marble on box i is \frac{i}{9}. Since we replace the marble after drawing, the probability remains the same for each draw. Therefore, the probability of drawing three consecutive red marbles from box i is:
P(R_{3} | B_{i}) = \left(\frac{i}{9}\right)^{3}
Now, we can calculate the probability of drawing three consecutive red marbles (we can trivially discard i=0):
P(R_{3}) = \frac{1}{10} \cdot \sum_{i=1}^{9} \left(\frac{i}{9}\right)^{3} = 0.277
Now, we want to calculate the probability that the fourth marble drawn from the same box will also be red, given that we have drawn three consecutive red marbles. Let’s denote this event as R_{4} (for the fourth red marble). We need to compute P(R_{4} | R_{3}).
We can apply Bayes’ theorem:
P(R_{4} | R_{3}) = \frac{P(R_{3} | R_{4}) \cdot P(R_{4})}{P(R_{3})}
We know that P(R_{3}) = 0.277, and P(R_{3} | R_{4}) = 1 (because the probability of getting 3 red marbles consecutive given that we have 4 red marbles consecutive is 1). Therefore, the only missing part is P(R_{4}) wich can be calculated as follows:
P(R_{4}) = \sum_{i=1}^{9} P(R_{4} | B_{i})P(B_{i})
P(R_{4}) = \frac{1}{10} \cdot \sum_{i=1}^{9} \left(\frac{i}{9}\right)^4 = 0.233
finally, we can calculate P(R_{4} | R_{3}):
P(R_{4} | R_{3}) = \frac{1 \cdot 0.233}{0.277} = 0.84
We can simulate this experiment as follow:
event_a_and_b <- replicate(100000, {
box <- sample(x = 0:9, size =1)
marbles <- sample(c(rep("red", box), rep("blue", 9 - box)), 4, replace = TRUE)
all(marbles == "red")
})
event_b <- replicate(100000, {
box <- sample(x = 0:9, size =1)
marbles <- sample(c(rep("red", box), rep("blue", 9 - box)), 3, replace = TRUE)
all(marbles == "red")
})
mean(event_a_and_b) / mean(event_b)[1] 0.8350382Let’s denote the event of choosing box 9 as B_{9}. We want to calculate P(B_{9} | R_{3}). We can apply Bayes’ theorem:
P(B_{9} | R_{3}) = \frac{P(R_{3} | B_{9}) \cdot P(B_{9})}{P(R_{3})}
The probability of getting three consecutive red marbles given that we have chosen box 9 is P(R_{3} | B_{9}) = \left(\frac{9}{9}\right)^3 = 1. The probability of choosing box 9 is P(B_{9}) = \frac{1}{10}. The probability of getting three consecutive red marbles is P(R_{3}) = 0.277. Therefore, we can calculate P(B_{9} | R_{3}) as follows:
P(B_{9} | R_{3}) = \frac{1 \cdot \frac{1}{10}}{0.277} = 0.36
We can simulate this experiment as follow:
event_a_and_b <- replicate(100000, {
box <- sample(x = 0:9, size =1)
marbles <- sample(c(rep("red", box), rep("blue", 9 - box)), 3, replace = TRUE)
all(marbles == "red") && box == 9
})
event_b <- replicate(100000, {
box <- sample(x = 0:9, size =1)
marbles <- sample(c(rep("red", box), rep("blue", 9 - box)), 3, replace = TRUE)
all(marbles == "red")
})
mean(event_a_and_b) / mean(event_b)[1] 0.363971How many ways are there of getting 4 heads when tossing 10 coins?
using the binomial coefficient:
{10 \choose 4} = \frac{10!}{4! \cdot 6!} = 210
How many ways are there of getting 4 heads when tossing 10 coins, assuming that the 4th head came on the 10th toss?
If we know that the 4th head came on the 10th toss, then we must have gotten exactly 3 heads in the first 9 tosses. We can count the number of ways to get 3 heads in 9 tosses using the binomial coefficient:
{9 \choose 3} = \frac{9!}{3! \cdot 6!} = 84
Six standard six-sided dice are rolled.
The number of outcomes is 6^{6} = 46656
The first die can be any of the six numbers. The second die must be one of the remaining five numbers (since we can’t repeat the number from the first die), the third die must be one of the remaining four numbers, and so on. Therefore, the number of outcomes in which all six dice are different is:
The number of outcomes is 6 \cdot 5 \cdot 4 \cdot 3 \cdot 2 \cdot 1 = 720
The probability of getting six different numbers when rolling six dice is:
P(E) = \frac{720}{46656} = 0.0154
A box contains 5 red marbles and 5 blue marbles. Six marbles are drawn without replacement.
The number of ways of drawing 6 marbles is:
{6 \choose 10} = \frac{10!}{6! \cdot 4!} = 210
The number of ways of drawing 4 red marbles and 2 blue marbles is:
{5 \choose 4} \cdot {5 \choose 2} = \frac{5!}{4! \cdot 1!} \cdot \frac{5!}{2! \cdot 3!} = 50
The probability of drawing 4 red marbles and 2 blue marbles is:
P(E) = \frac{50}{210} = 0.238
We can simulate this experiment as follow:
event <- replicate(100000, {
marbles <- sample(c(rep("red", 5), rep("blue", 5)), 6, replace = FALSE)
sum(marbles == "red") == 4 && sum(marbles == "blue") == 2
})
mean(event)[1] 0.23855